This product is currently participating in a promotional offter.
Add to Cart
Start Order
Buy Now(In stock)
Custom Order
Payment:
This product is a virtual commodity with no physical object
description1
Zipper closure
1/4 zip athletic pullovers for men. Stretchy, lightweight, fast-drying
fabric for superior performance.
REGULAR FIT - US standard sizes. An athletic fit that sits close to the body
for a wide range of motion, designed for optimal performance and all day
comfort.
FEATURES - Quarter zip closure;Thumbholes on long sleeves to keep them in
place during workout
Challenges in Traditional Data Integration
① Non-Real-Time Data Data transferred via ETL lags behind that of production systems and often requires reprocessing due to inconsistencies or quality issues.
② High Implementation Costs Centralizing data from hundreds of databases using Schema-on-Write demands massive time, labor, and financial resources while unable to achieve real-time synchronization.
③ Performance Bottlenecks Generally, each business database needs to undertake data reporting, synchronization of the integration platform and other tasks. ETL processes burden source databases, degrading operational performance.
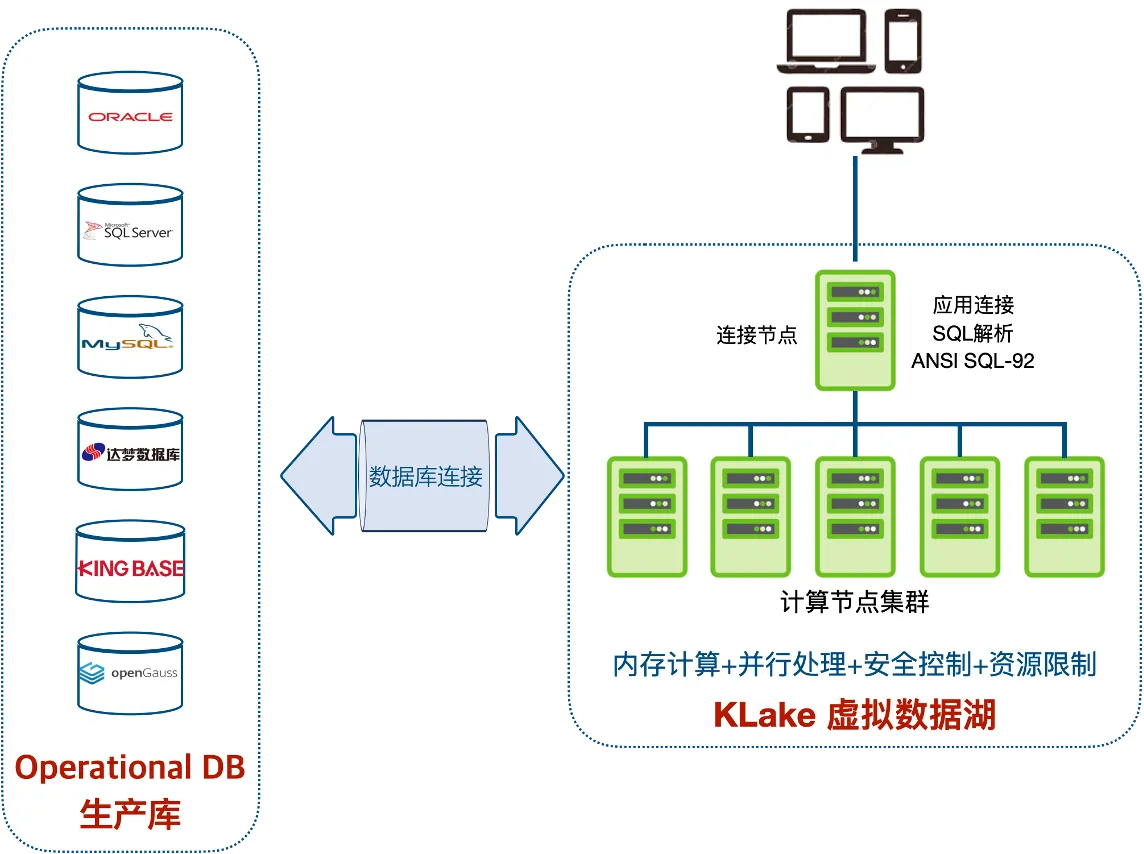
KLake Virtual Data Hub
Unlike ETL’s reliance on physical data movement, KLake employs data virtualization to create an invisible "data fabric" that unifies real-time data from disparate sources. This virtual layer delivers a holistic, dynamic view of enterprise data without physical replication.
① Schema-on-Read: It dynamically parses data schemas during queries, performs transformations and filters on demand, and unifies organizational databases into a logically centralized source.
② Multi-Source Reporting & Analytics: It enables real-time cross-database queries for reports, thereby eliminating stale or inaccurate data from intermediate repositories.
③ Offload Source Databases: It parses SQL into sub-queries, executes them via ODBC drivers across source systems, and performs computations (joins, aggregations) within KLake’s MPP cluster—reducing load on production databases.
④ AI-Driven Metadata Management: It automatically identifies table structures, field definitions, and relationships by using AI-powered metadata discovery tools, minimizing manual configuration.
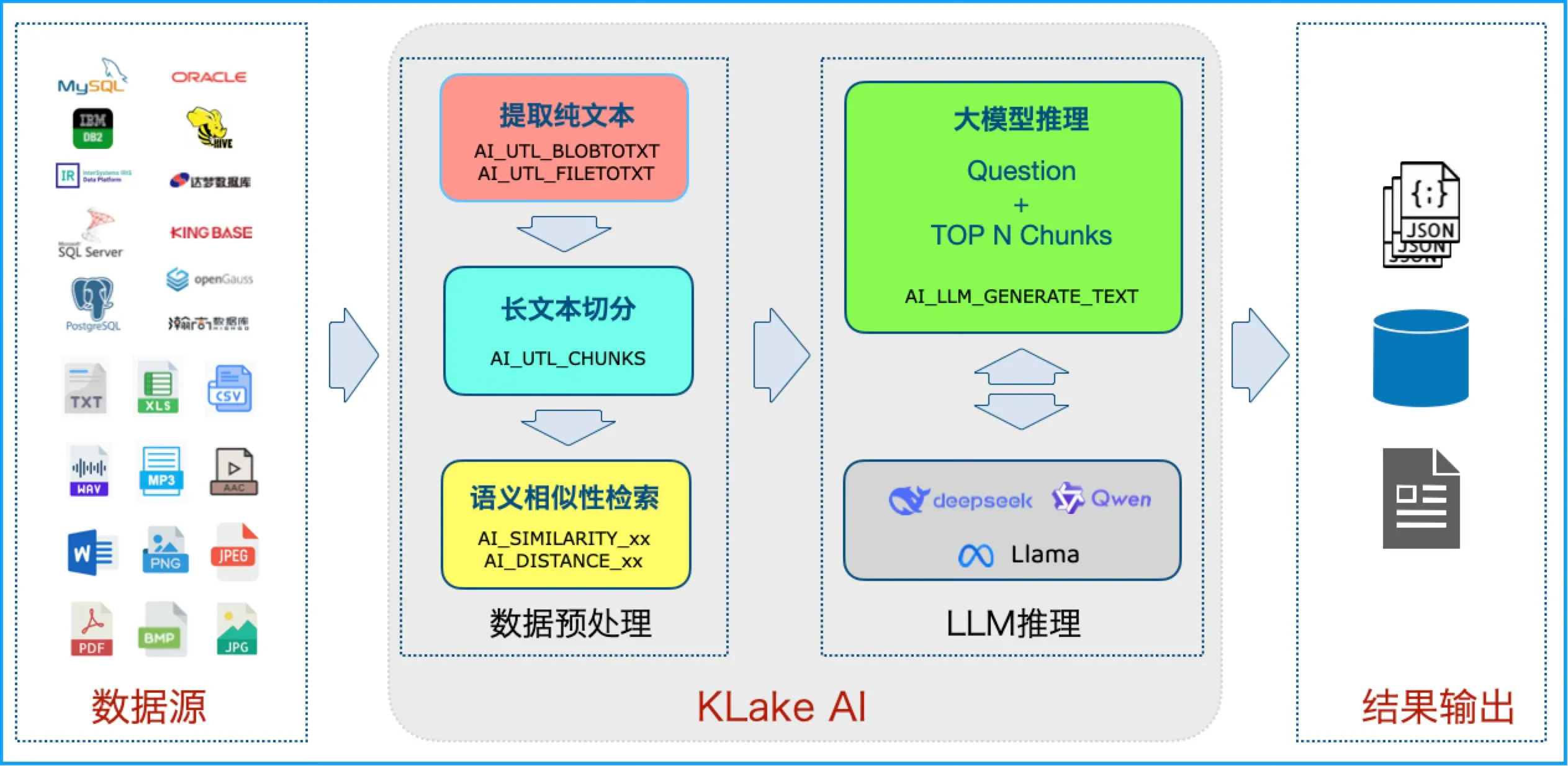
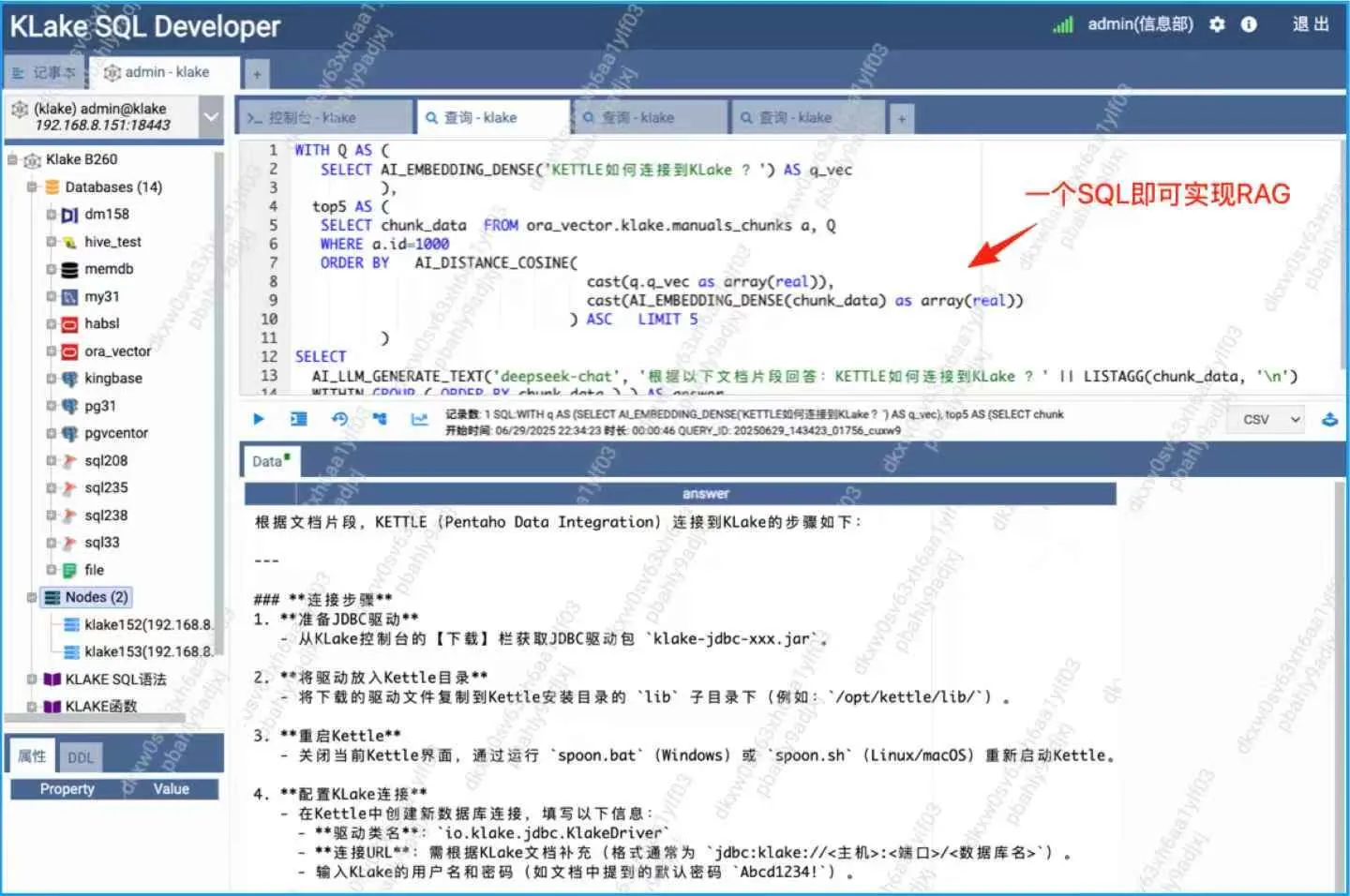
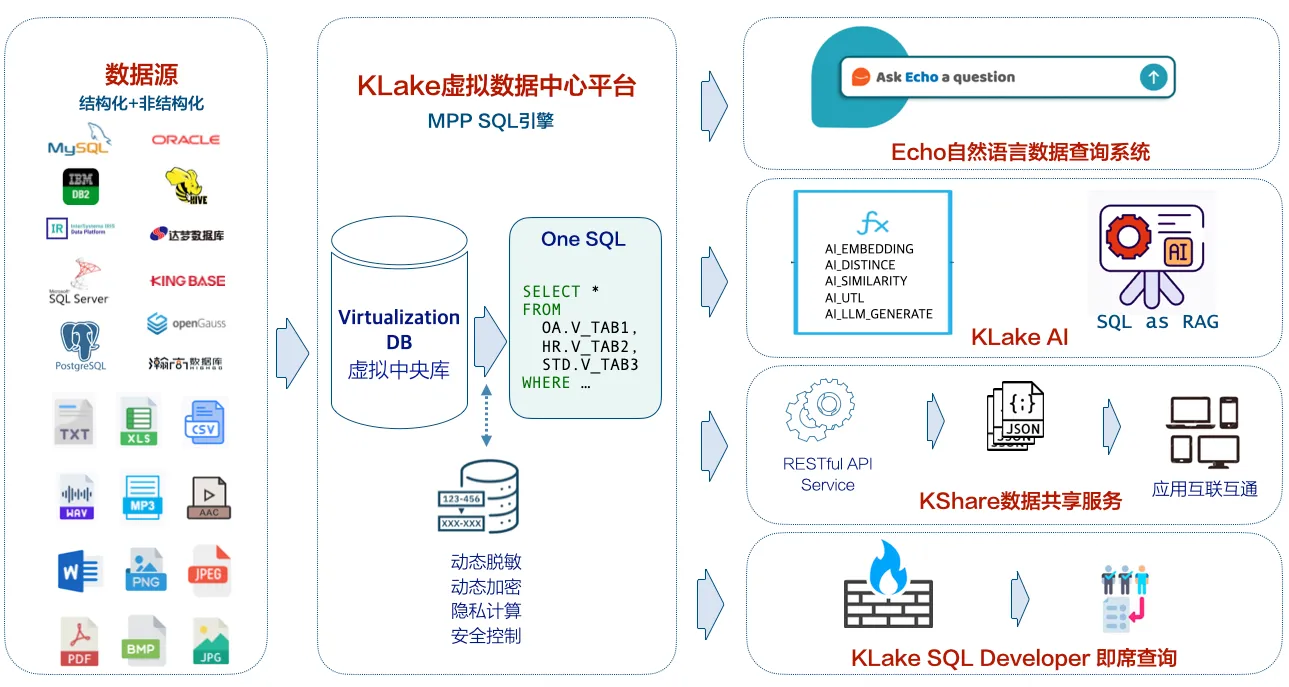
⑥ Vector-free library: Say bye to consistency problem completely, through AI_EMBEDDING_DENSE and other SQL functions, real-time text /PDF/WORD/ picture/audio to vector without persistent storage.
⑦ SQL is AI, zero programming to achieve full scene application
a> Semantic Search: AI_SIMILARITY_DENSE(' patient complains of chest pain ', medical record text, ‘cos') searches similar medical records in seconds;
c>RAG Q&A: AI_LLM_GENERATE_TEXT('DeepSeek-chat', < splice question + similarity fragment >) Output result reports and suggestions.
pinpoint relevant data.
KLake Technical Architecture
KLake is an MPP (Massively Parallel Processing)-based SQL compute cluster. It does not store data but dynamically parses/executes SQL queries and returns results. The platform provides centralized security controls and resource management
Supported Data Sources
At least the following data sources are supported:
Third-Party Tool Integration
KLake integrates with BI/ETL tools via JDBC/Python drivers, enabling real-time data access without physical movement. Supported tools include:
① FineReport
Users can achieve 3x faster SQL performance and visualize terabyte-level data in real time by querying sources mapped by KLake (e.g., HIS, PACS).
②Metabase
Users can write SQL in Metabase to analyze real-time data across KLake connectedsystems.
③ Kettle
Users can schedule ETL tasks in Kettle to query KLake for real-time data extraction and reporting.
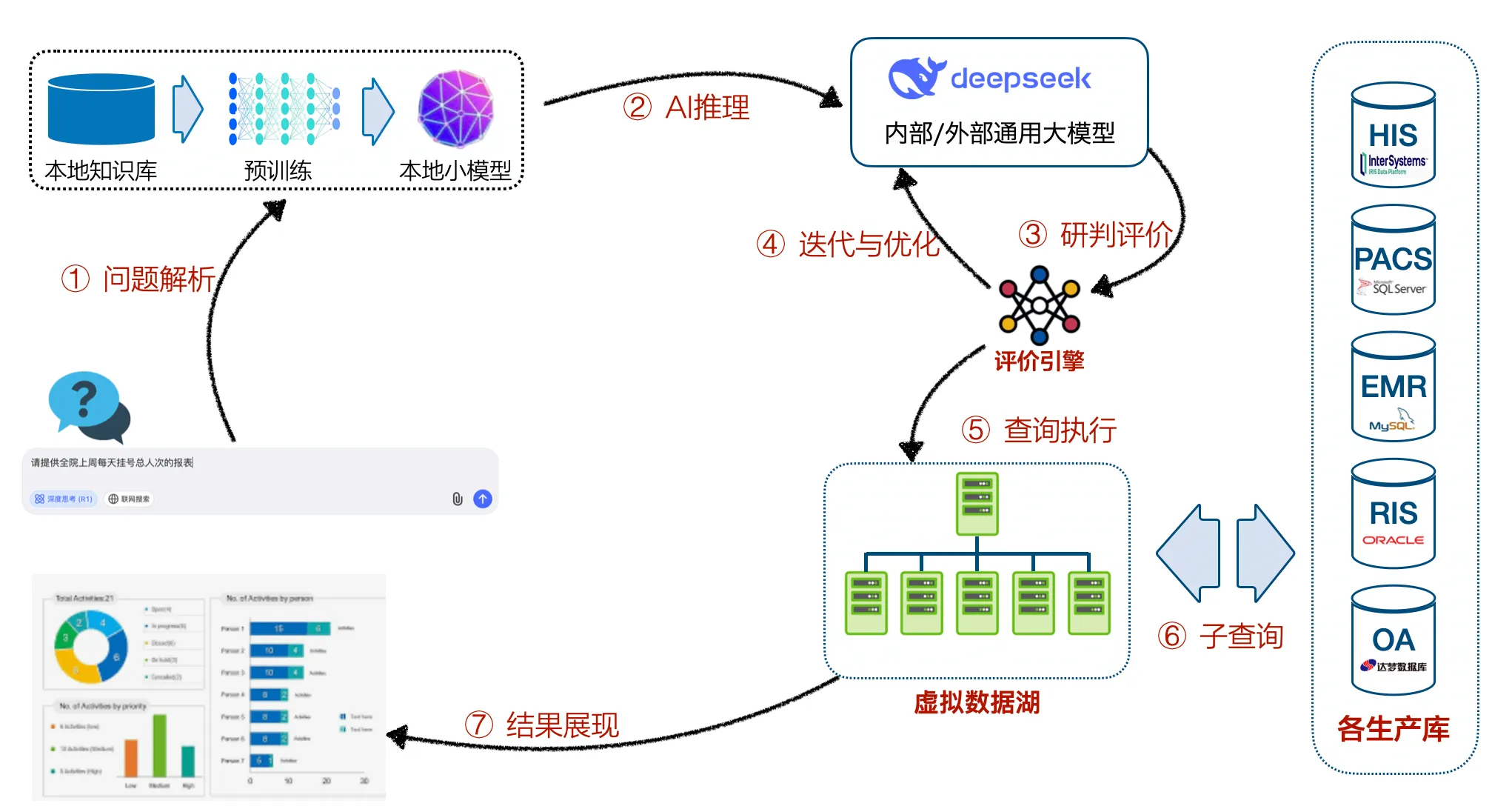
Natural Language Reporting System
Powered by the DeepSeek R1 open-source LLM, this system allows users to query enterprise reports via natural language. Key features:
Natural Language Understanding : Process queries like "Show last month’s department performance."
Multi-Dimensional Analysis : Filter by time, department, or metrics.
Visualization : Present results as charts or text.
Continuous Optimization : Improve accuracy via user feedback
Local Knowledge Base : Builds a unified metadata view for private data retrieval.
Local Small Model : Trained on the knowledge base to enable vector-based semantic search.
Enterprise LLM (DeepSeek) : Combines local knowledge with LLM reasoning for natural language-to-SQL conversion.
Evaluation Engine : Validates SQL accuracy before execution.
Multi-Platform Access : Web and mobile interfaces for seamless user interaction.
In order to realize the above functions, this scheme adopts Data Fabrictechnology architecture. Compared with the traditional ETL and data warehousemode, KLake dynamically connects various databases in the enterprise througha metadata management driven intelligent network, avoiding intermediate linkssuch as data migration and cleaning, and significantly improving the real- time and consistency of data use.
Quantifiable Benefits
Faster Integration: KLake’s data virtualization enables rapid integration of diverse data sources, boosting data consolidation speed by 3×.
Inventory Optimization: Real-time unified views improve inventory accuracy and timeliness, increasing efficiency by 40% and reducing waste.
Lower O&M Costs: Eliminating data replication and point-to-point links simplifies architecture, cutting operational costs by 50%.
Quicker Reports: High-performance queries and visualization tools reduce report generation time from hours to minutes, improving efficiency by 60%+.
Faster Data Access: Real-time cross-system queries cut response times by 80%, enabling faster business insights.
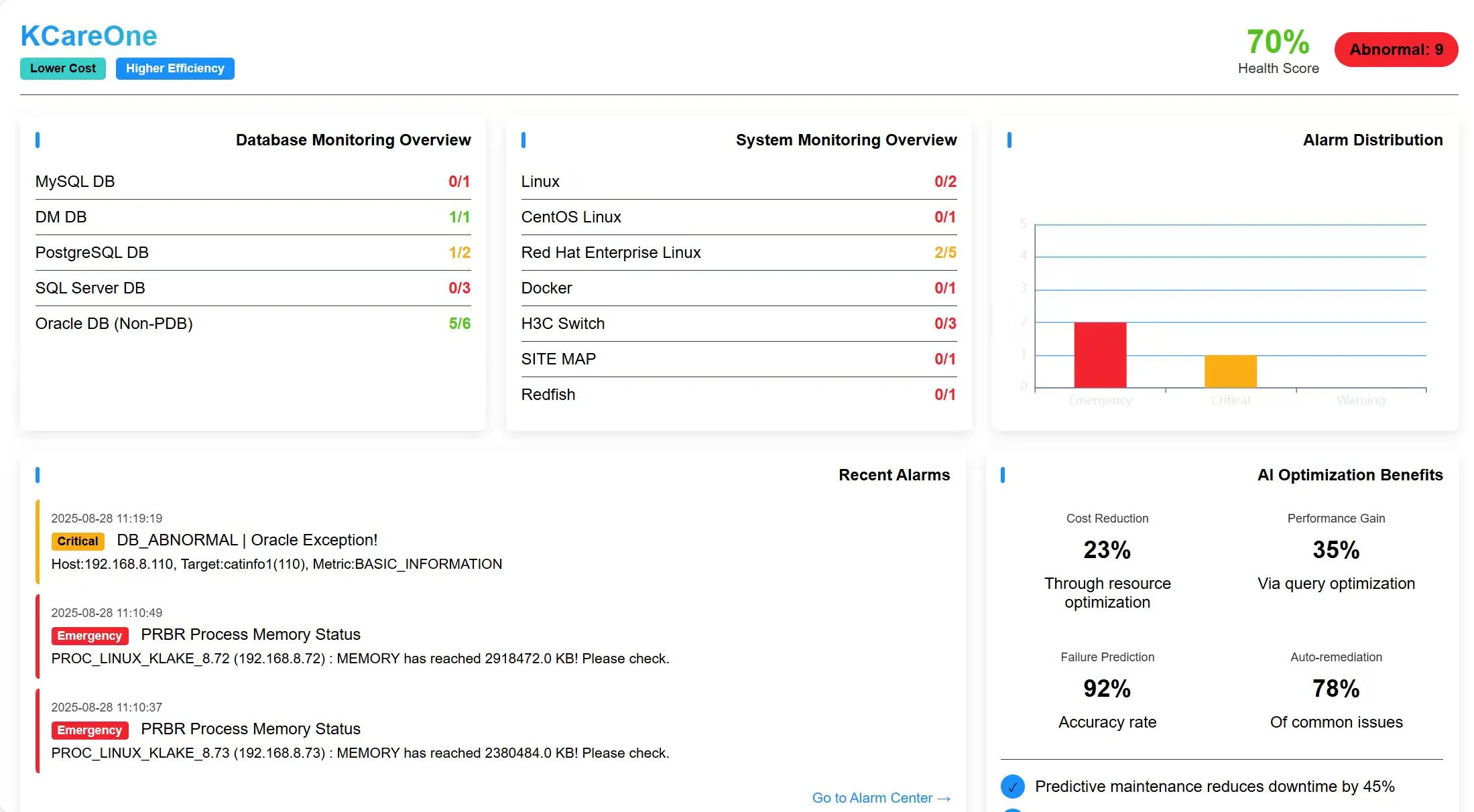
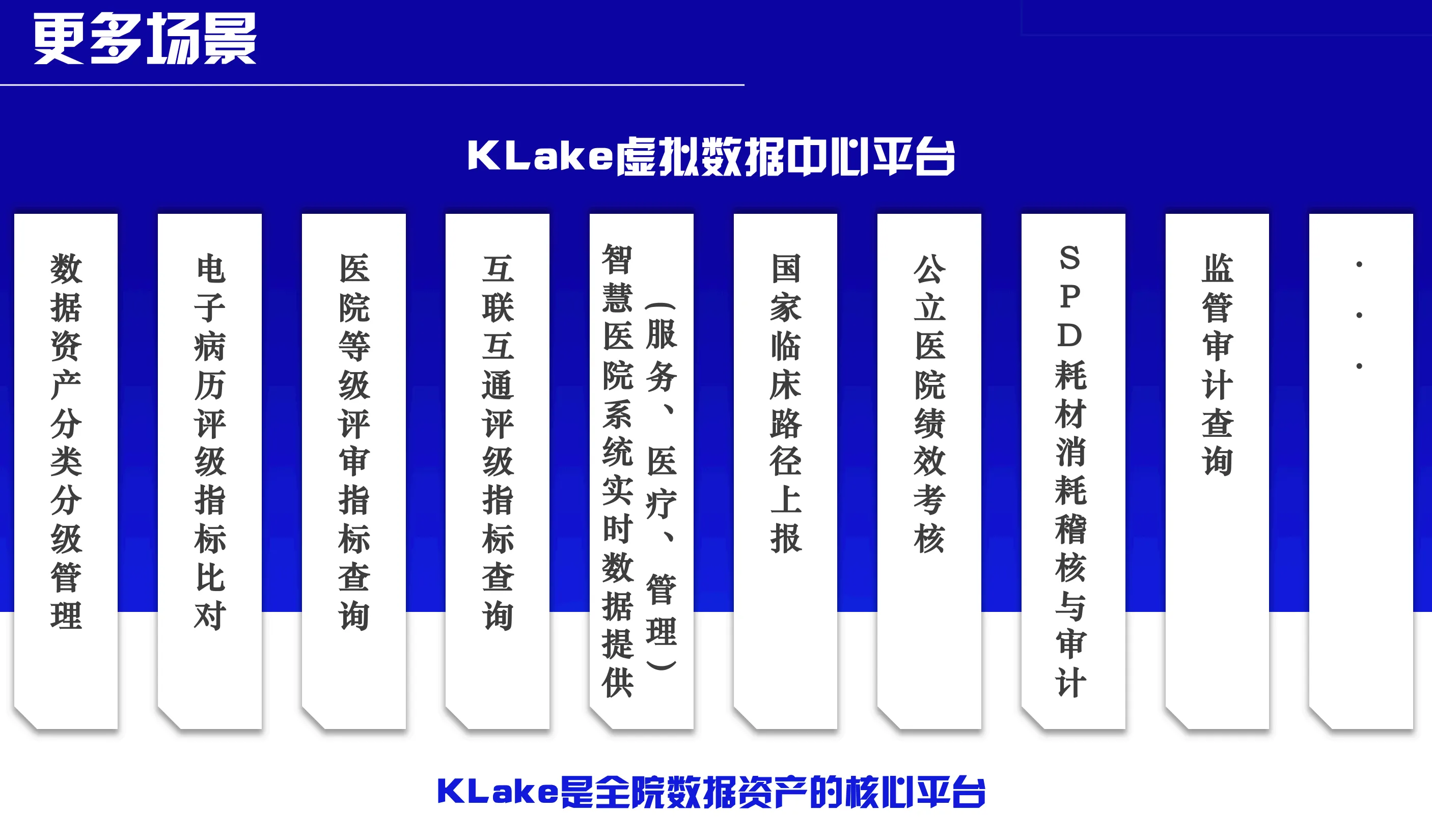
KLake Use Cases in Healthcare
①Relieve Production Database Load: KLake offload SQL computations from HIS/PACS systems to KLake’s MPP cluster.The daily data reporting of HIS and PACS systems, as well as the synchronization of various data, has led to the core production database to be overwhelmed.
② Cross-System Benchmarking: Users can execute single-SQL comparisons across multiple databases for hospital ratings (e.g., EMR interoperability).
③ Natural Language Queries: Users can input query requirements in daily language (such as "Query the number of emergency visits last month") or input diagnostic keywords (such as "Type 2 diabetes patients"), and the system will automatically parse the intention and return the results.
④ Real-Time Data for Smart Hospitals: KLake unify hospital-wide data into a virtual database to power real time smart healthcare applications. KLake consolidates all database resources across the hospital into a single virtual database, thus perfectly addressing issues of data real-time performance and comprehensiveness and serving as the core data infrastructure foundation for the hospital.
Support order samples, customization, wholesale direct, and complete payment.
If the product you look for does not have corresponding customized content, pls fill out the
form below to contact us, and we will reply ASAP.


.webp)


.webp?x-oss-process=image/resize,w_100/quality,q_100)




