How to Enable Non-Technical Personnel to Query Data Conveniently Has Become the Most Pressing Issue for Every Organization
Traditional data query methods rely heavily on IT departments and technical staff, leading to slow response times and low efficiency. Today, Te Information’s newly launched Echo Natural Language Data Query System is redefining the relationship between humans and data through conversational interaction.
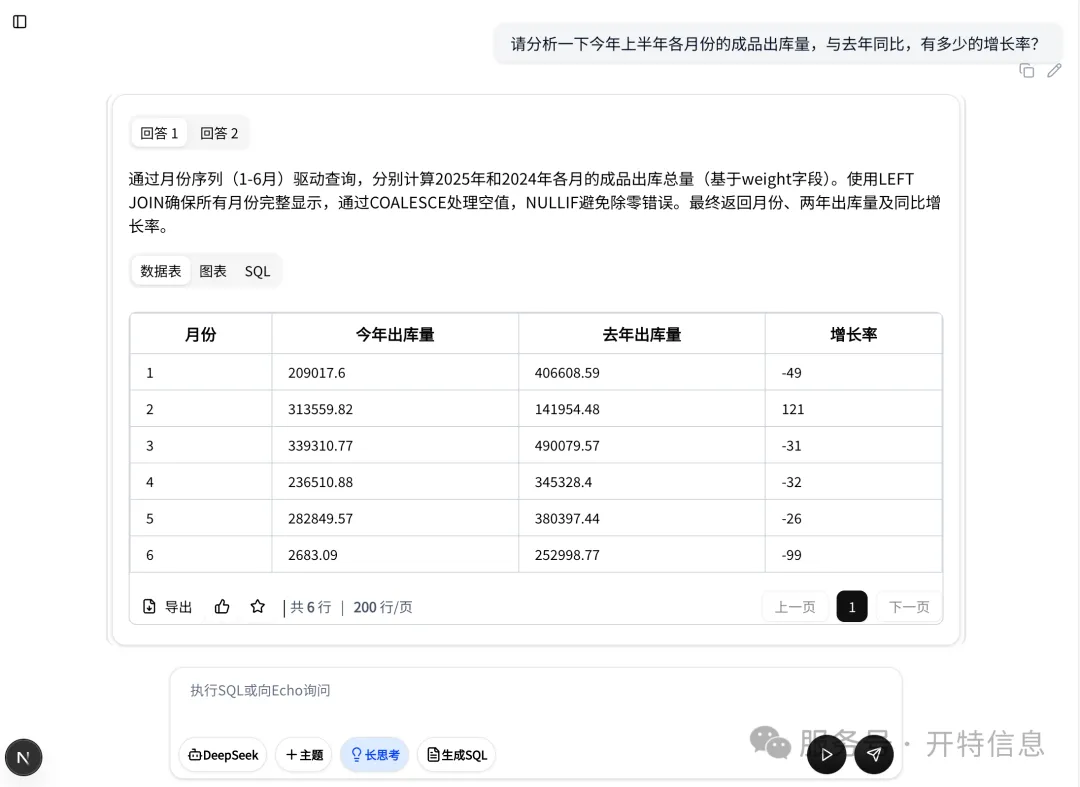
Echo is an enterprise-grade natural language data query platform. Leveraging powerful semantic understanding and local knowledge reasoning capabilities, it allows users to complete complex cross-database and cross-table data queries, as well as automatically generate SQL statements or return results directly—simply by “asking questions” in everyday language. There’s no need to learn SQL; non-technical personnel can easily get started and “query data like chatting,” truly realizing the vision of “everyone can be a data analyst.”
In traditional models, data querying often faces the following challenges:
- No programming skills, no way to start querying: Most business users don’t understand SQL, let alone database structures.
- IT resource constraints, slow responses: Engineers are stuck handling a flood of ad-hoc data requests, drowning in a “sea of needs.”
- Scattered data, difficult integration: Data silos across multiple systems make cross-database analysis of business issues nearly impossible.
- High training thresholds, slow deployment: Many Text2SQL solutions require large volumes of training data, resulting in long deployment cycles and high costs.
Echo was created to completely solve these problems!
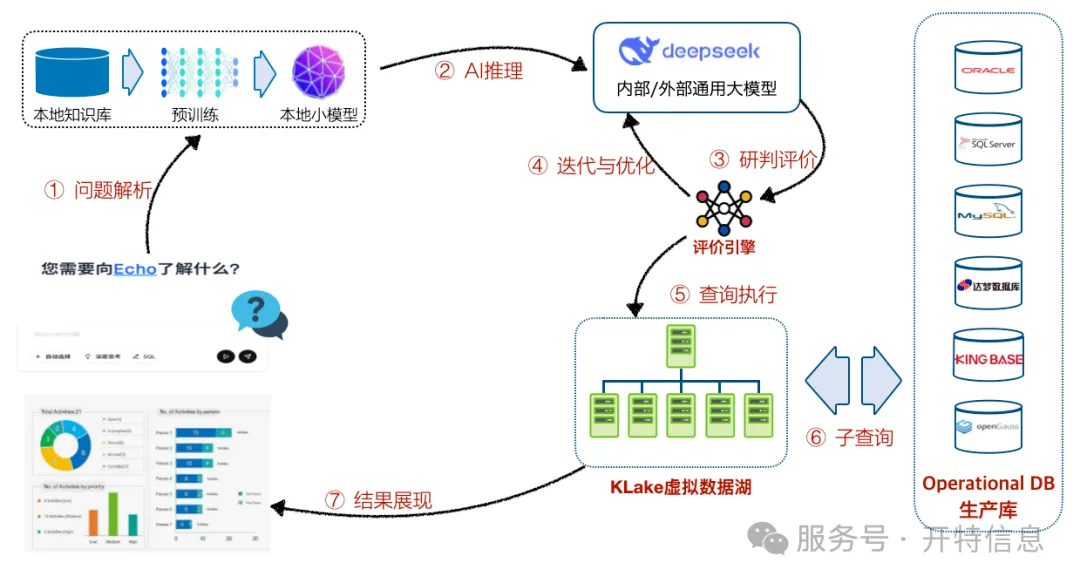
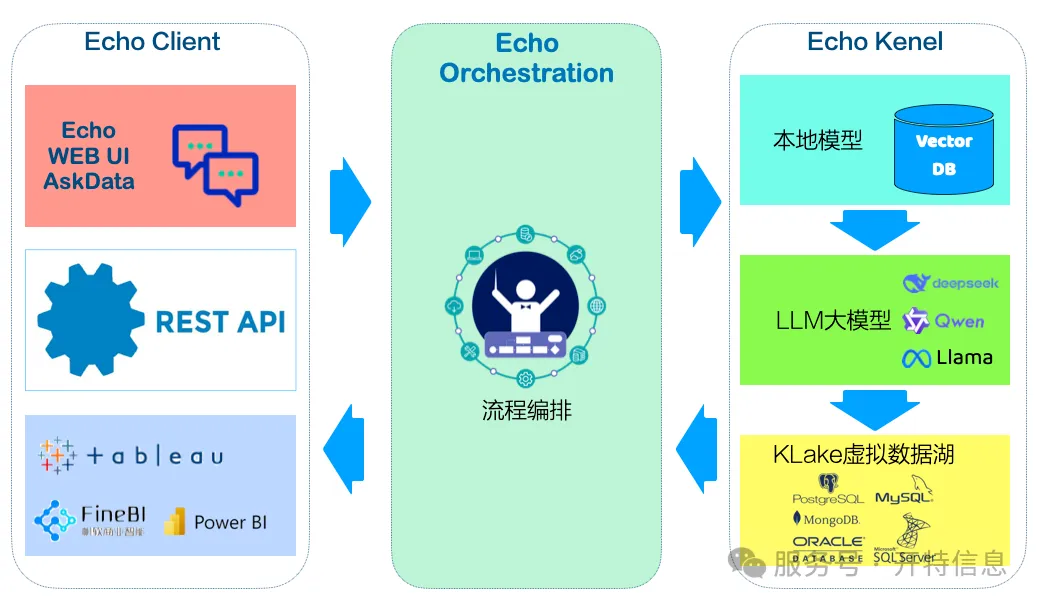
Echo not only “understands” natural language but also boasts robust data adaptation capabilities and efficient query performance:
- Extensive Data Source Support: Compatible with mainstream databases such as ORACLE, SQL Server, MySQL, DB2, Dameng, Kingbase, and openGauss, as well as file formats like Excel and CSV—adapting to multi-source heterogeneous data.
- Cross-Database Query Capability: A single user question can query multiple databases simultaneously, enabling true “cross-system collaborative analysis.”
- Direct Result Presentation or SQL Generation: It can output visualized results for business users to use directly, or generate SQL statements for technical staff to further refine.
- High-Performance MPP Engine: Built on a Massively Parallel Processing (MPP) architecture, queries have minimal impact on the performance of source databases.
- Ready-to-Use with No Training Required: No large volumes of historical Q&A data are needed for deployment. It offers strong adaptability and can be flexibly implemented in various business scenarios.
- Fuzzy Semantic Recognition & Multi-Path Prediction: Even if a question description is unclear, the system provides multiple alternative answers based on semantic analysis, helping users gradually clarify their intentions.
The application of Echo not only greatly improves data efficiency but also fundamentally transforms how data is used within enterprises:
- Free Up IT Resources to Focus on Governance: IT teams are no longer stuck passively handling data requests; instead, they can concentrate on data governance and standardization.
- Empower Business Users to Accelerate Response Times: Business staff can access key data on their own without waiting, speeding up decision-making.
- Boost Data Utilization: The shift from “waiting for others to query” to “proactively asking” enhances the conversion of data into value.
- Enhance Security Auditing & Permission Control: It supports auditing of all query activities and integrates with permission systems to ensure compliance with the principle of least privilege.
In the future, data querying will no longer be an exclusive skill of technical personnel but a basic skill for all business participants. Echo was developed to break down technical barriers and truly implement “data equity.”